Summary on World Models by David Ha & Jürgen Schmidhuber
Introduction
In this post I have tried to point out the key ideas presented in the paper World Models by David Ha & Jürgen Schmidhuber. Anyone looking for a quick glimps on this SOTA RL model or a memory-refreash on previous read, would be an ideal audience.
This is also part of a paper review assignment of the course CSE6369.
Thank you for taking the time to read this summary! ❤
Summary of the Paper
The image of the world around us, which we carry in our head, is just a model. Nobody in his head imagines all the world, government or country. He has only selected concepts, and relationships between them, and uses those to represent the real system. - Jay Wright Forrester
What we perceive at any given moment is governed by our brain’s prediction of the future based on our internal model. - Nortmann et al., 2015; Gerrit et al., 2013.

This paper mainly proposes an RL model that is able to solve CarRacing and VizDoom challenge very successfully. To achieve this feat, the proposed model has three key modules. Fist, it perceives the high-dimentional world around it as a low-dimensional representation. Then, it has a internal memory that stores the previous states of the world and the agents action, and can be used reliably to predict future states in the environment given a particular agent action. Also, the model has a small controller, that is responsible for selecting suitable actions to maximize the reward obtained from the environment.
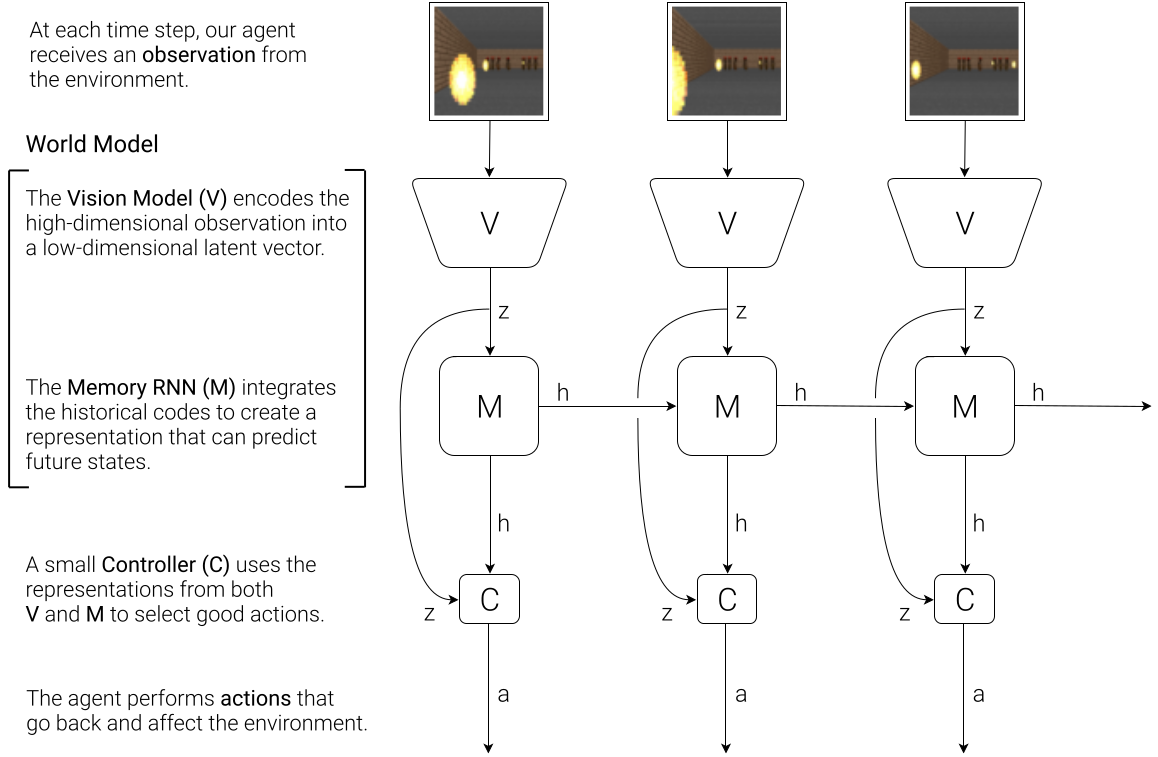
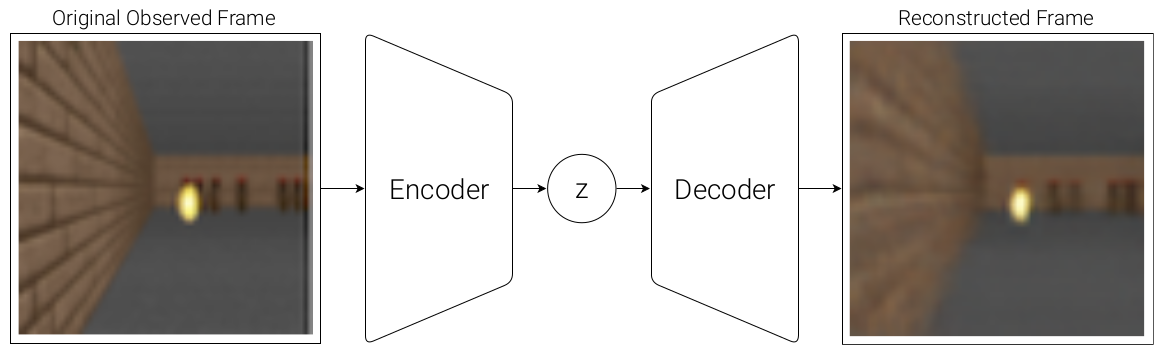
Vision(V)
Here, a standard Variational Autoencoder (VAE) is used to model the Vision (V) part. The VAE can be used to compress the observation (a 2D image in this case) into a small low-dimensional latent vector (z).
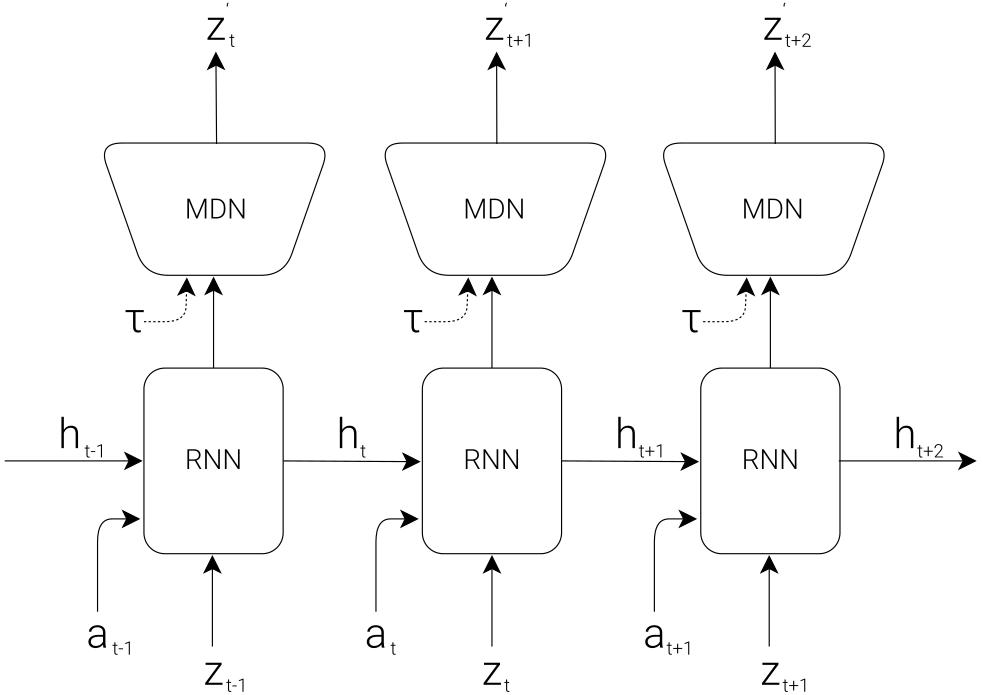
Memory (M)
An RNN model with Mixture-Density-Network (MDN) is used to model M. The RNN part is responsible to track the previous action-observation history and can be used to predict the future z. But, here instead of predicting the future z deterministically, an MDN is used to predict the probability distribution p(z) of z. Then, z is simply sampled from this predicted p(z) using a hyper-parameter Temperature.
Controller (C)
The controller itself is a small single layer neural network that maps the z and hidden state from the RNN (h) to action (a), so that the reward is maximized.
V + M + C
This is how the final model looks like after assembling V, M and C modules.
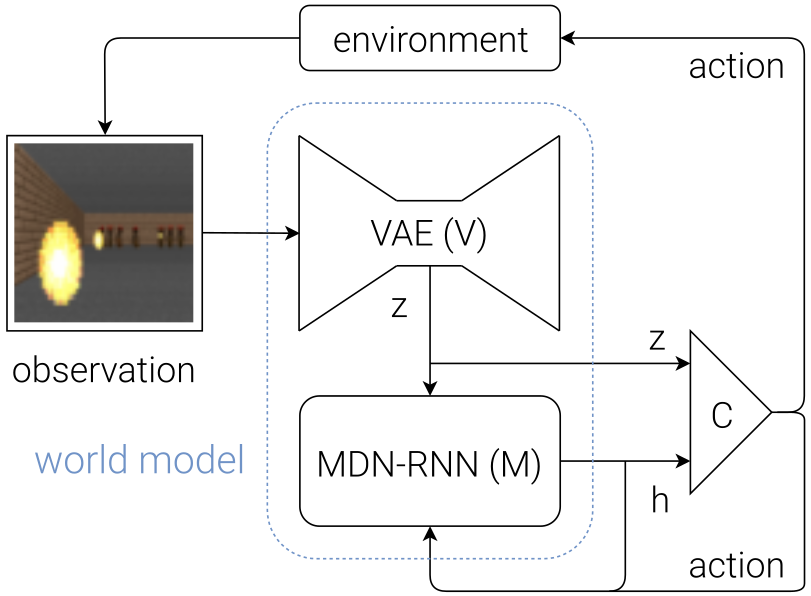
Key Achievements of this Work
- As the agent’s selection of action considers the current observation(as low-dimensional latent-represnation) and the previous history (hidden state of RNN), the agent can act instictively (as a baseball batter acts when he hits the ball).
- Because of the generative nature of the MDN-RNN, an agent can generate its own dream-world and train itself in that dream-world. Then, this trained agent can actually be ported into the actual enviroment. This can be really useful for robots to be trained in a simulated world, and then deployed into the real world.
Ending Thoughts
- Both the games used to evaluate the performance of this model has some form of external reward signals (driving time, alive time etc). But, what if we want to solve some task that do not have any such defined reward. For example, how can we solve perceptual unity paradigm using world model? Also, the game environemtn is very small in terms of diversity and complexity. How can we sample an open world to train the V model effectively?
- The authors touch these point by refering to intrinsic motivation (IAC model by P. Oudeyer) which can be used to guide the agent iteratively to sample it’s surrounding world iteratively. However, the actual result of this combination is yet to be reported.
- The iterative training procedure requires the M model to not only predict the next observation x and done, but also predict the action and reward for the next time step. This may be required for more difficult tasks. For instance, if our agent needs to learn complex motor skills to walk around its environment, the world model will learn to imitate its own C model that has already learned to walk. After difficult motor skills, such as walking, is absorbed into a large world model with lots of capacity, the smaller C model can rely on the motor skills already absorbed by the world model and focus on learning more higher level skills to navigate itself using the motor skills it had already learned.