Summary on Grounded Language Learning in a Simulated 3D World by Karl Moritz Hermann et. al.
Introduction
In this post I have tried to point out the key ideas presented in the paper Grounded Language Learning in a Simulated 3D World by Karl Moritz Hermann et. al. This paper proposes a way to train AI agents through simple but diverse instructions given in human language and allowing the agent to actively explore the provided environment. For people who are looking for some backgorund or inspiration on training an embodied agent that would acquire world knowldege via human language would be an ideal audience.
This is part of a paper review assignment of the course CSE6369.
Thank you for taking the time to read this article! ❤
My Summary
Embodied AI, Active Exploration, Curriculum Learning
The Environment
The described environment has integrated language channel into a 3D simulated world. A very simple environment setup can be comprised of two connected rooms, each containing two objects. When training an agent, multi-word instructions can be issed withion the environemnt in usual human language, such as “pick the object X in each episode”. During training, the agent experiences multiple episodes with the shape, colour and pattern of the objects themselves differing in accordance with the instruction. Thus, when the instruction is pick the pink striped ladder, the environment might contain, in random positions, a pink striped ladder (with positive reward), an entirely pink ladder, a pink striped chair and a blue striped hairbrush (all with negative reward).
The Agent
In the above environment, an agent perceives its surroundings via a constant stream of continuous visual input and a textual instruction. Most importantly, the agent can control it’s own movement to decide where to focus its visual sensors and thus controlling exploration of it’s surroundings. The agent’s primary objective is is to find a policy which maximizes the expected discounted return.
The Model
The model is a single neural network that has four different modules as folloing
- Visionv (V) Module: A convolution based encoder.
- Language (L) Module: LSTM based encoder to encode the given instructions.
- Mixture (M) Module: Decider to combine the vectors from V and M.
- Action (A) Module: Comprises of two-layer LSTM and receives input from the M. It computes a probability distribution over possible motor actions π(atjst), and a state-value function approximator V al(st), which computes a scalar estimate of the agent value function for optimisation. To learn from the scalar rewards that can be issued by the environment, the agent employs an actor-critic algorithm. Parameters are updated according to RMSProp.
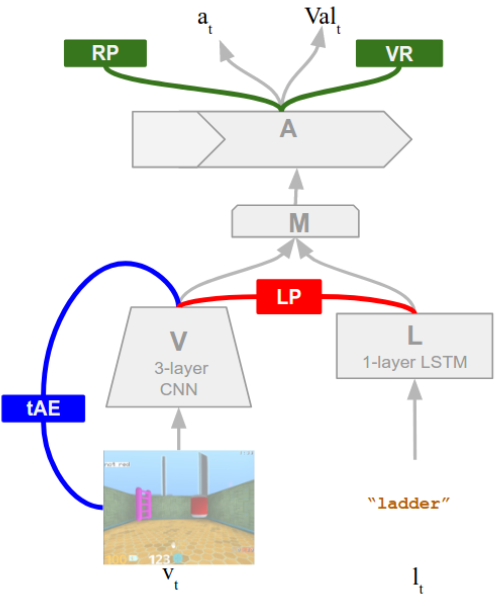
There are two auxiliary network as follows,
- Temporal Autoencoder (tAE): This is designed to illicit intuitions in our agent about how the perceptible world will change as a consequence of its actions. V and the hidden states from A is passed to a deconvolution network to predict the next visual frame.
- language Prediction (LP): This network acts as a bridge between the viual and linguistics modality by estimating instruction words given the visual observation , using model parameters shared with both V and L. The LP network can also make the agents behaviour more interpretable as the agent emits words that it considers to best describe what it is currently observing.
Experiments and Outcomes
- Unsupervised learning via auxiliary prediction objectives facilitates word learning. Results demonstrate that auto-regressive objectives can extract information that is critical for language learning from the perceptible environment, even when explicit reinforcement is not available.
- Word learning is much faster once some words are already known
- A consequence of the agent’s facility for re-using its acquired knowledge for further learning is the potential to train the agent on more complex language and tasks via exposure to a curriculum of levels.
- Agent shows evidnece of reusing known words to understand novel phrases (red-square, blue-triangle -> red-triangle) and can use apply learned knowledge into a novel scenario (larger than square 1 -> larger than triangle 1).
- Curriculum learning is necessary for solving more complex tasks.
- this agent demonstrates an ability to ground language referring not only to single (concrete) objects, but also to (more abstract) sequences of actions, plans and inter-entity relationships. Moreover, in mastering the Next to and In room tasks, the agent exhibits sensitivity to a critical facet of many natural languages, namely the dependence of utterance meaning on word order.
Main Contributions
I think that allowing the agent to explore the environment on it’s own with the goal to solve a task is the key. Also this paper tries to get ahead of language tests like turing test and Winograd Challage which requires higher level of language understanding to begin with. Here, the paper discusses about how this language understanding ability might be formed in the first place.
Ending Thoughts
If we consider the main goal is to design an human like AI, probably learning to understand grounded-language is still a more advanced task (appears in human in around 12-18 months). To properly exploit curriculum learning, simpler sensor based tasks could prove to be useful. May be we can consider tasks that a new born babies (1-3 months old) learn to do?
Also, even though the envinment seemed to have some diversity in terms of various instructions and objects, the training procedure seemed very much dependant on enviroment provided reward rewards. Could it have learned this same words/languages if maximizing the reward was not it’s sole purpose?