Summary of the Final Day Lecture of CSE6369 by Dr. Deokgun Park
Introduction
In this post I have tried to summarize the final talk in the course CSE6369 by Dr. Deokgun Park. This serves as a brief walkthrough of the journey throughout the semester. The talk covers all the major ideas that we have covered with our paper summaries throughout the semester. Additionally, Dr. Park had presented some of his own hypotheses and a proposed model that tries to solve the universal intelligence problem. THis is basically for my own future reference, possibly might be helpful for future student of the lab.
This is also part of a paper review assignment of the course CSE6369.
Thank you for taking the time to read this summary! ❤
Part I: Theories about intelligence
The talk began with the definition of intelligence and based on this definition various levels of biological intelligence. From the paper the universal intelligence we have the definition as Intelligence measures an agent’s ability to achieve goals in a wide range of environments. And there are three levels of intelligence where level I intelligence are purely rule-based biological organisms and do not learn anything in it’s own life cycle(e.g. earthworm). Evolution steps up to modulate the genetics of such organisms to make it better suited in future generations. Level II intelligence, the organisms can learn tasks within its own life cycle, though that is somehow limited by the fact that they do not have any well-formed language (e.g. rabbit, dog). As a result an individual of level II, can only learn something by first hand experience or association. Finally in level III, the organism has a very well developed linguistic model which allows it to absorb knowledge that may cover spaces and time that would otherwise prove to be inaccessible (e.g. human). This gives us the formal definition of the HLAI as An agent has HLAI if there exists symbolic representations for every possible sensory input and action sequence, such that the agent can update behaviour policy equally whether it receives the symbolic description or the sensory-motor experience itself.
Part II: Evaluation of HLAI
The second part of the talk covers the evaluation process of the HLAI. If someone claims that they have created a HLAI, how can we evaluate their claim? Since the ability to acquire language allows an agent to learn any other arbitrary tasks in a proper environment, we can say that Given the proper environment, if the agent can acquire human language, we can say it has the capability to achieve HLAI. The SEDRo environment tries to provide such a simulated environment that allows simulation of experiences that a typical human baby goes through. In this environment we can test the agent on experiments such as “Perceptual Unity Completion” inspired by psychology to keep track of the agent’s progress. These types of experiments are special because they are open-ended with no external rewards, require human experiences and also require the agent to have longitudinal learning ability.
A Possible Model: mHPM
The third part of the talk discusses a possible model that can simulate a level a III intelligence. For such a model we would need heterarchical structure to allow feedback and hierarchical information representation to allow for context storage in various levels. This model is illustrated in figure 1. As the lower level layers process the incoming vectors in a predictive manner, the generated summary is fed to the higher level to be processed in a similar manner but at a lower frequency. The lower layer receives the predictive context from the upper layer that helps the lower layers to make predictions with increased accuracy.

One nice property of this model is that the weight updates happen locally and as a result the network can be trained a lot more efficiently which conforms with slower clock-speed biological organisms. Also, this same structure can be used to combine multimodal neural signals to generate multimodal neural summary vectors. Hence, it can address the heterarchical structure as well. FInally, this network update will be modulated with the reward signal such that the networks memorization of the vectors is enhanced proportional to the reward it received. As a result the agent will be prone to generate behaviors that have some positive reward history.
There are three auxiliary components to this model such as instinct module, reward center and Hippocampus as episodic memory writing. In brief, the instrict module is something that is like farmwire, the reward center (innate and acquired) is like the dopamine secretion and hippocampus to allow storing events like what I had at last night’s dinner (it only happened once, but I remember the experience).
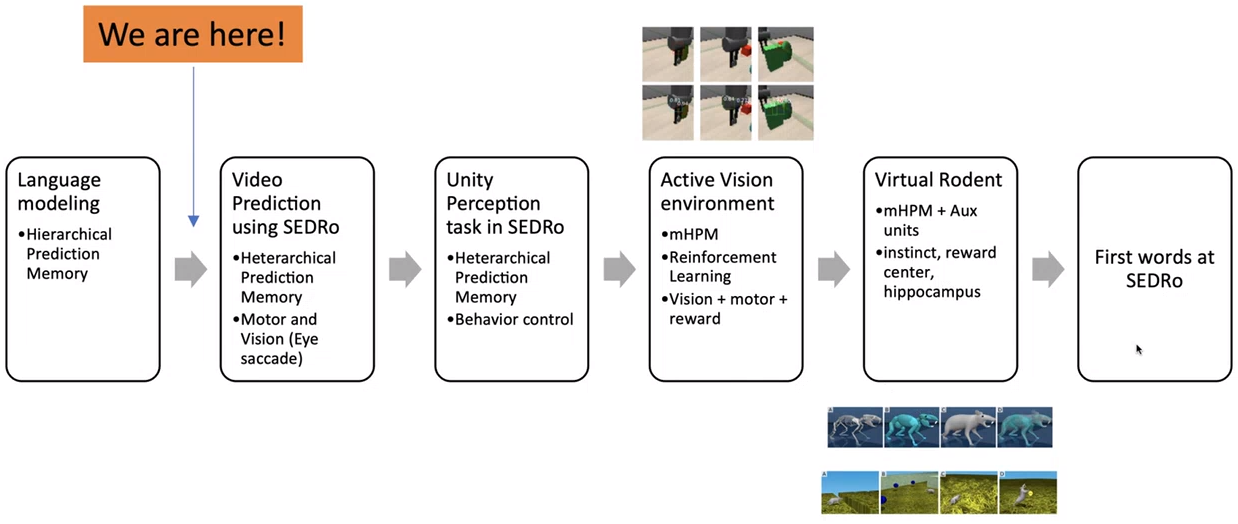
Future Directions
The last part of the talk illustrates a possible road map to achieve HLAI and the stages are shown in figure 2.
Ending Thoughts
I personally am a bit skeptical about how this model can handle the action or motor prediction in practice. We might need some kind of goal generator at the very top of the model hierarchy and then use the degree to which a certain action contributes towards that goal as the measurement of that action’s justification.