Summary of Dileep George's Keynote Speech
Introduction
In this post, I have summarized the major points of Dileep George’s keynote speech at the Human-Level AI Conference in Prague in August 2018. Here, he presents two new networks (RCN and SchemaNet) which are inspired by biological brains and consequently aim towards solving AGI. I have added links for most of the reference papers and books which are mentioned during this presentation for quick access.
This post is mainly directed towards myself and for anyone out there who would like to have a quick re-cap of this talk. Thank you for reading! ❤
1. Talk
The full talk can be found here.
1.1 What Is Intelligence
Intelligence is the ability TO MODEL the world and TO ACT purposefully on that model.
1.2 Old-Brain and It’s Similarity to Current Application-specific Networks
Old-brain is a very good function approximator or pattern-recogniser, however, it does not create a complex world map of the environment around it. Rather than reasoning behind it’s actions, it relies on reactive behaviours to perform a wide variety of tasks.
Hence, it has the following limitations:
- Needs lots of training data — it evolved on an evolutionary scale.
- Low generalization.
- No model of the world.
- Illusion of intelligence — actually what we think of intelligence are a product of those reactive circuits inside them. This brain (frog going for ants displayed on a screen) only does things instinctively, rather than reasoning on what it is doing. Conventional AI (CNN, RNN etc.) resembles a lot to the old-brain.
1.3 New-Brain and How It Can Reason
New-brain is not just a scaled up version of the old-brain. The neo-cortex that wraps around the old-brain is structurally very much different. It has the following characteristics:
- Needs very few training data — it evolved on an evolutionary scale.
- High generalization.
- Learn a causal model of the world.
- Can solve common-sense problems, eg., Alan is hammering a nail into a wall, Brian is pounding a nail into the floor. Which nail is horizontal?
1.4 Generative models can be possible candidate for modelling human-brain
Brain is a structured probabilistic model that can be queried dynamically or in different ways.
1.5 Presented Paper I: Generative Model for Vision (Recursive Cortical Network)
This paper can be found
here.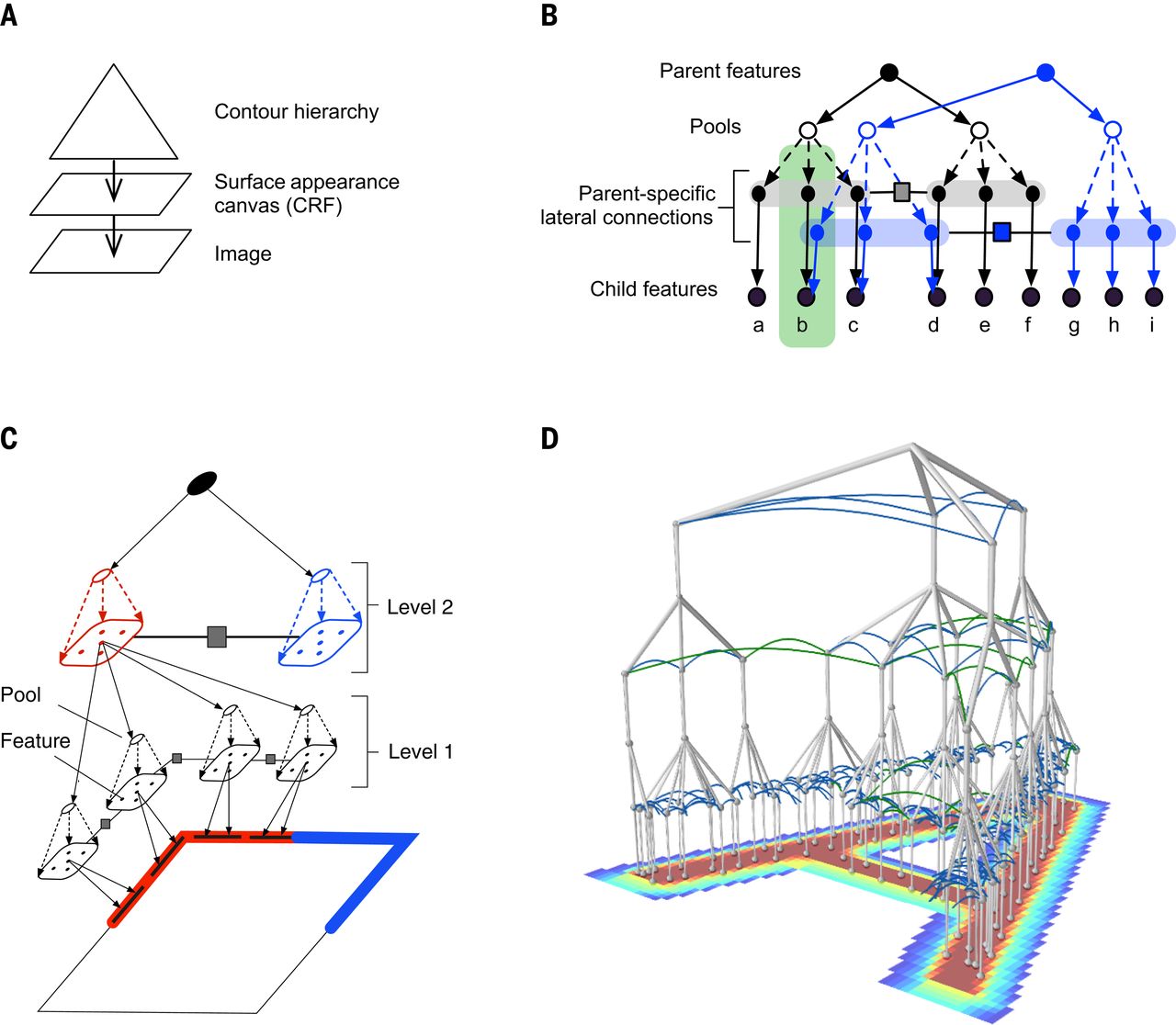
- New contribution of RCN compared to conventional CNN.
- It is a generative model, hence it can reason both ways.
- It has lateral connection.
- Addresses the following issues.
- Contour continuity via lateral interactions.
- Factorized representations of contour and surface.
reference paper

Example of how human visual system performs factorized contour and surface to recognise weird structures. - Border-ownership coding.
- Top-down object based attention.
reference paper,
reference book

Example of how human visual system can separate out overlapping objects even though they are occupying the same space. - Inference dynamics.
Example of how human visual system can separate out overlapping objects even though they are occupying the same space. - Forward pass messages -> is a technique to do inference in a probabilistic generative model. It has the same performance speed as our brain.
- For each top level node, assume all other top level nodes are off. Gives an upper bound on the likelihood of each node.
- Backward pass
- Assemble partial MAP configurations for high-scoring nodes at the top. These produce object segmentations.
- Forward pass messages -> is a technique to do inference in a probabilistic generative model. It has the same performance speed as our brain.
1.6 Presented Paper II: Generative Model for Dynamics (Schema Network)
This paper can be found here.
It is a graphical network which can be thought of as an object-oriented Markov Decision Process (MDP). Thinks of the world as made of different objects, their interactions and having cause-effect, rather than the usual pixel-base approach. Hence, it can generalize better than Deep Q Learning.
1.7 Neuroscience -> Graphical Model -> Back to Neuroscience
This is like fact checking, like solving a puzzle and retrace back which part of a model explains some specific routine that is performed in the neocortex.
1.8 Question-Answer Session
What is the difference between RCN and Hinton’s Capsule Network?
- CapsNet requires a lot more training data.
- It needs to know beforehand how many objects it will expect in a scene.
- It requires a lot more training data if the experimental setup changes slightly (To go from 1 object to 2 object scenes, the required training sample changed from 60k to 1M).
What would be an optimal representation (which may be a human brain uses) to encode the world?
- He is using the framework of probabilistic graphical models combined with programs. It can be called Probabilistic Programming.
2. Discussion After Watching the Talk with the Lab Members
The presenter claims that current ML algorithms are like old-brain. He also says that old-brain is not generalized enough. But can we make an old-brain with the current conventional models?
- Because of the exponential data hypothesis (that when the number of domains increases, the required training data increases multiplicatively rather than additively), it would take too many data samples to train a conventional model to learn multi-tasking, so it can be as generalized as the old-brain.
It seems like the presenter (and also Yann LeCun et al.) gives a lot of weight to the sample efficiency. That is use as little data sample as possible to master a task, which removes bias from the learned network, saves them from overfitting on the training sample, and generalizes well.
- I think that using less data samples might not be that big of a deal. Rather, routines like Efficient Data Representation and Storing and Knowledge-Sharing from Different Domains might prove to be more important.
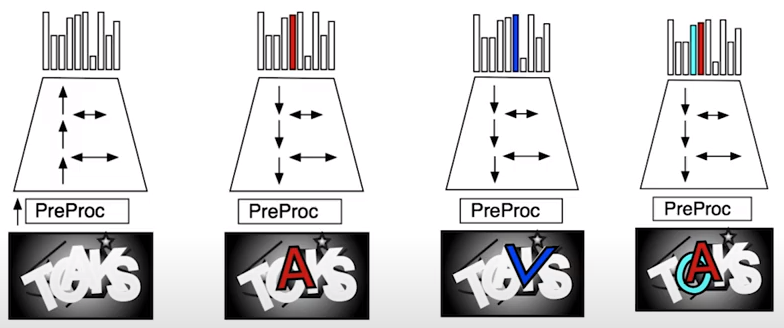
In which fundamental criteria, RCN would fail to solve SERDo?
- While breaking the CAPCHA problem, RCN has to deal with a fixed set of charaters or symbols. So, it can generate a probability distribution for each of those symbols. However, SEDRo is an open-world environment and the possible number of symbols or objects that can be found there is technically unbounded. Hence, to generate some kind of prediction or recognition, RCN would have to generate probablity distribution for the unbounded number of symbols.